대표님과 이야기 하던 도중 갑자기 뜬금없이 대표님께서 컴퓨터에서 사용하고 있는 Random 에 대해 알고있냐고 물어보시더군요....
당연히 난수를 발생시키는 모듈이죠 하고 끝인줄 알았으나 이야기를 하다보니 생각보다 제가 모르는 내용이 정말 많더군요...
그래서 오늘은 Random 모듈에 대해서 좀 알아보려고 합니다.
Random?
정말 익숙한 모듈이죠..
개발을 하다가 무작위 수가 필요하다 싶으면 아주 자연스럽게 사용하는 모듈이죠...
하지만 여러분 이 랜덤모듈로 인해 발생하는 숫자는... 사실 정말 랜덤하게 뽑힌 숫자일까요?
컴퓨터에서는 이 랜덤모듈을 통해 숫자를 어떻게 뽑아내고 있는걸까요?
난수란 무엇인가?
우선 컴퓨터에서 랜덤한 숫자를 뽑아내는것을 알아보기 전 우리는 난수의 의미에 대해 다시한번 생각해봐야할 필요가 있습니다.
난수란 뭘까요?
http://aispiration.com/statistics/stat-random-number-generator.html
데이터 과학에서 난수에 대한 정의를 다음과 같이 표현하였습니다.
정의된 범위 내에서 무작위로 추출된 수를 일컫는데 , 이때 난수는 누구라도 그 다음에 나올 값을 확신할 수 없어야 한다.
또한 난수생성기로 만들어진 난수는 다음과 같은 특성을 지녀야 한다고 합니다.

저희들이 생각하기에 정말 당연한 정의죠...
하지만 여기서 저희가 핵심으로 확인해야할 부분은 이부분입니다.
누구라도 그 다음에 나올 값을 확신할 수 없어야 한다.
이게 무슨소리인가 싶으실 겁니다.
당연히 누구라도 그 다음에 나올 값을 모르니 난수가 아닌가?
그렇다면 컴퓨터에서 만드는 난수는 다음에 나올 값을 예측이 가능하단 말인가?
난수를 만들었는데 생성된 숫자가 특성 영역에 본포되어있다는 뜻인가? 라고 말입니다.
Puseudo-Random (의사난수)
Psueudo Random (의사 난수)에 대해 잠깐 알아보도록 하겠습니다.
Puseudo-Random이란 랜덤같이 보이지만 실제로 랜덤이 아닌것을 말합니다.
이말이 무슨뜻이냐... 이곳에서 나오는 값들은 똑같이 같은 장소, 다른 시간에서도 만들어 낼수 있다는 소리입니다.
컴퓨터에서 사용하는 난수 발생 알고리즘은 바로 이 Puseudo Random 알고리즘을 이용한 것입니다.
그렇다면 Puseudo Random 에는 어떤 종류가 있을까요?
중앙 제곱법
폰 노이만이 1949년에 고안해낸 방법입니다.
임의의 숫자를 제곱한 다음 이 숫자의 일부분을 가져와서 새로운 난수를 만들어 내는 방법이죠
예를들어 3자리 임의의 난수를 발생시킨다면..
|
페이즈
|
대상값
|
제곱값
|
난수
|
|
0
|
2345
|
5499025
|
990
|
|
1
|
6492
|
42146064
|
460
|
|
2
|
7531
|
56715961
|
159
|
이런식으로 중앙에 있는 값을 빼오는것이죠...
이건 예측이 너무나도 쉬운 알고리즘이죠? 그렇기 때문에 이방법은 현재 사용하지 않는 방법입니다.
선형 합동법
가장 기본적인 난수 발생 방법입니다.
C언어의 경우 srand() rand() 함수
JAVA의 Random 클래스가 선형 합동법으로 구현되어있죠...

선형 합동법의 관계식은 다음과 같습니다.
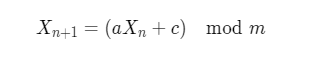
선형 합동법의 특징은 이전에 생성된 난수를 활용한다는 것이며 최대 m 만큼의 경우의 수를 가지므로 최악의 경우 m만큼의 반복 주기를 가진다는 것입니다.
선형 합동법은 계산이 굉장히 간단하고 빠르기 때문에 초창기부터 컴퓨터에 널리 사용된 방법이였습니다. 하지만 난수에 주기성이 있고 생성되어 나오는 난수들 사이에 상관관계가 존재하기 때문에 마지막으로 생성된 난수와 그 외 변수들만 알면 다음에 생성될 난수들을 모두 예측할수 있는 문제가 있습니다.
더욱 큰 문제는 그 변수들이 ANSI C 표준으로 정해져있어 누구든지 다 알수 있다는 소리입니다..
즉 난수에 대한 지식이 어느정도 있는 사람이 rand 함수의 결과를 보면 다음 난수가 무엇인지 미리 예상을 할수 있다는 소리입니다.
따라서 이 알고리즘은 난수가 예측되도 상관이없는 경우나 임베디드처럼 메모리를 많이 사용하지 못하는 제한된 상황에서 주로 사용됩니다.
메르센 트위스터
현재 프로그램에서 쓰이는 더 정교한 난수 생성 방법입니다.
C++, Excel, MATLAB, Python, R 등 여러 프로그램에서 쓰이고 있는 알고리즘이죠.. 1997년 마츠모토 마코토와 니시무라 다쿠자가 개발한 알고리즘입니다.
메르헨 트위스터라고 명명한 이유는 이 알고리즘의 난수 반복 주기가 메르센 소수이기 때문에 그렇게 명명했다고 합니다.
메르헨 트위스터의 알고리즘 동작원리는 다음과 같습니다.

XOR 시프트
LFSR 을 기반으로 한 난수 알고리즘입니다.
메르센 트위스터와 원리는 비슷하지만 구현이 훨씬 간단하고 작동이 빠르기 때문에 종종 사용됩니다.
메르센 트위스터보다 구현이 간단하고 작동이 빠르지만 잘 사용되지 않는 이유는...
TESTU01 이라는 난수 품질 테스트 프레임워크가 있습니다만... 이게 그 품질테스트에서 통과를 하지 못했다는 문제가 있기 때문입니다..
이것을 통과해야 ANSI C 표준이 될수 있거든요...
때문에 이를 개량한 알고리즘들이 나오기 시작했는데 그중 하나가
V8, SpiderMonkey, JavaScriptCore 등 메이저 JS 엔진들이 선택한 난수 생성 알고리즘인 XOR 시프트 128+ 라는 알고리즘입니다.
해당 알고리즘은 2016년 11월에 발표되었으며 관련 논문내용은 아래 링크를 클릭하시면 됩니다.
https://vigna.di.unimi.it/ftp/papers/xorshiftplus.pdf
결론
처음에는 대표님과 잡담하면서 다루었던 주제였는데... 본격적으로 찾아보기 시작하니 정말 엄청나게 깊게 들어가야해서 깜짝 놀랐었습니다.
각 언어마다 채택하고 있는 난수 생성 알고리즘도 다르고...
컴퓨터에서 진정한 의미의 난수를 만드는것도 거의 불가능 하다는것을 알게 되었죠... 물론 최근에 미국에서 양자컴퓨터로 True Random을 만드는데 성공했다고하나... 양자컴퓨터는 대중화 되기에는 무리가 있죠....
이 내용을 공부하면서... 정말 많은 수학자들이 연구를 통해 다양한 라이브러리를 만들어 내고 있다는 것을 알게 되었습니다..
이분들 덕분에 저희들이 지금 편하게 코딩하고 있는거겠죠...? 정말 감사할 뿐입니다...
참고 사이트 :
컴퓨터가 만드는 랜덤은 정말로 랜덤할까?
이번 포스팅에서는 에 대해서 한번 이야기 해볼까 한다. 랜덤이란 어떤 사건이 발생했을 때 이전 사건과 다음 사건의 규칙성이 보이지 않는, 말 그대로 로 발생하는 패턴을 이야기한다. 우리가
evan-moon.github.io
'개발관련 > 정보' 카테고리의 다른 글
| 개발관련 - Postman (포스트맨) (0) | 2023.07.03 |
|---|---|
| 개발관련 - 코딩 테스트 사이트 추천 / 기업 코테용 프로그래머스 (0) | 2023.07.03 |
| 개발관련 - C언어 프로토타입(Prototype) (0) | 2023.07.03 |
| 개발관련 - 팀프로젝트 / 졸업 팀과제 조언 (0) | 2023.07.03 |
| 개발관련 정보 - 한줄 다중변수 선언의 유래 (0) | 2023.07.02 |